Complex Data Structures in PL/SQL
10 / Nov 2002This article was modified from its original published form. The most recent modification was on2014-09-25.
In an ideal software development project, the development environment (languages, tools, and libraries) will be chosen that best suits the nature of the problem domain and the skills of the professionals involved. In the real world, the development environment is dictated by any number of constraints—the most common being that the project is a modification to or enhancement of an existing project. Just because one cannot—for whatever reason—use the language most suited to the solution does not mean that one can’t take lessons from those languages.
At one of my previous jobs, I worked on a project where the code was written in PL/SQL called by a C driver. Many developers don’t think much of PL/SQL because they believe that it performs slowly, or because its functionality is limited, or because they simply do not know or understand the language. For this project, PL/SQL performed the tasks (mostly data manipulation) as fast or faster than an equivalent C implementation could have done because there were fewer context switches and no network communication involved. (If you aren’t familiar with PL/SQL, see the accompanying article.
PL/SQL is not without its limitations, mostly surrounding complex data structures. These limitations presented what seemed to be an insurmountable roadblock to the project—and the time-frame of this subproject did not allow for the language to be changed to one where the data structures required could be represented more “naturally”.
The subsystem in question required that the time-series data be viewed in ways which were not supported by SQL queries on the original data; it was necessary to restructure the data. This was a larger problem than originally anticipated, and the eventual solution to the problem came from an interesting combination of techniques. In the end, I adapted data structures that are more naturally represented in languages like C or C++ than in PL/SQL.
The Shape of the Problem
| Type | Start | End | Value |
|---|---|---|---|
| ABC | 2001-06-01 | 2001-06-01 | 1 |
| DEF | 2001-06-01 | 2001-06-05 | 15 |
| ABC | 2001-06-01 | 2001-06-03 | 3 |
| GHI | 2001-06-02 | 2001-06-03 | 10 |
The data was stored in the database as multiple records representing the data class, the starting and ending dates, and the value. Records could have any value (positive or negative) that spans any amount of time. Multiple entries of the same data class for overlapping time periods could be present. Table 1 shows how records for a five-day period might be present in the database. Figure 1 shows how these records could be considered on a timeline, which was how the requirements considered the records.
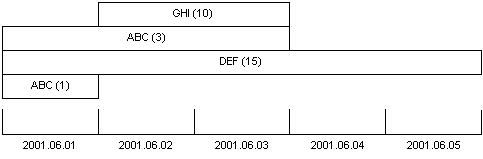
For our purposes, it was necessary to ensure that there was exactly one record
for each data class per day, containing the proportionate value that had
occurred on that day. If a record crossed multiple days, that record should be
considered as multiple daily records with proportional value. Since record
GHI spans two days with a total value of 10, the program had to treat it
as if it were two separate GHI records, each of value 5. Similarly,
there would be a total of three ABC records—and the the first record would
have value 2 because that’s the total of the portions of ABC records
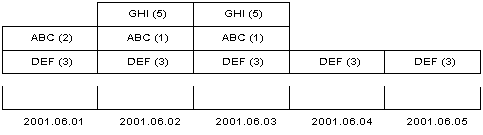
on that date. Table 2 shows how the data needs to be reorganized on
a daily basis. Figure 2 shows the same information against a
timeline. Compared against figure 1, the way that the records have
been massaged becomes clear.
| Date | Type | Value |
|---|---|---|
| 2001-06-01 | ABC | 2 |
| 2001-06-01 | DEF | 3 |
| 2001-06-02 | ABC | 1 |
| 2001-06-02 | DEF | 3 |
| 2001-06-02 | GHI | 5 |
| 2001-06-03 | ABC | 1 |
| 2001-06-03 | DEF | 3 |
| 2001-06-03 | GHI | 5 |
| 2001-06-04 | DEF | 3 |
| 2001-06-04 | DEF | 3 |
The easiest way to handle this problem would be to make it so that as each record is added to the original table, a trigger is fired that does the record division as noted in table 2 and adds the resulting records to a daily summary table. This solution has three major problems with it:
- The source table from which the original records were pulled was a very high volume table (and significantly larger than the sample data shown). Performing the split on a per-insert basis is computationally expensive, as each data class was generally expected to have at least one record and more likely several records each day (note that the examples given in this article assume only a single data source).
- The total volume of the data in the source table was very high, and the daily summary table would be at least as large, and most likely several times larger than the source table. Since these values are computed and are used in a single subsystem (this one) only, it didn’t make sense to use that much storage for what was essentially a temporary table.
- Each of the records in the data source table had a limited lifespan; once the analysis had been run on the record successfully, the analyzing program would never see it again. This would have increased the volume of the summary table unacceptably, because the summaries would have to be differentiated by visibility.
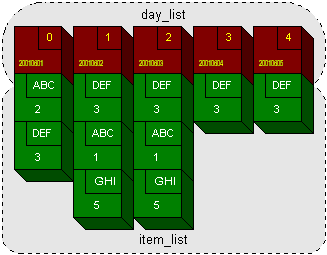
Without a temporary summary table, there was no way to do solve this problem with SQL queries (after all, the temporary summary table solved the problem of the data structure), so I needed to approach this programmatically. The data structure immediately suggested by figure 2 is an array of daily records, each of which has a dynamically-resized array of item records. If I were using a C-like language, I might use data structures like example 1 to solve this, which would produce an array like the one shown in figure 3.
typedef struct item_rec
{
char grouping[4];
double value;
} item_rec;
typedef struct day_rec
{
int date; /* yyymmdd */
item_rec *item_list;
} day_rec;
day_rec *day_list;
The Limitations of PL/SQL
This realization was very good, except for the fact that I couldn’t rewrite the program in C or C++ for this project1—there was no time to explore that option. The answer had to be reached, quickly, with the tools available. The simple solution was not an option because of PL/SQL limitations around complex data structures2. PL/SQL simply does not support nested collections. The array of structures containing arrays would not work in PL/SQL.
I looked through my library of PL/SQL books for a hint on how to solve this
problem, but no one had publicly tackled this problem. There was, however, a
hint toward a possible solution in Oracle PL/SQL Programming by
Steve Feuerstein with Bill Pribyl3. Steve Feuerstein has noted and
lamented this limitation of PL/SQL, and he presented a section on how
fixed-size multi-dimensional arrays could be simulated. He presented this as a
package allowing the developer to predefine (almost “allocate”) an array of
size r×c complete with accessor functions. Because the implementation is
hidden in the body of the package, it looks and works much like a
two-dimensional array in other languages.
The technique presented was to use a PL/SQL INDEX BY BINARY_INTEGER memory
table and map the two-dimensional array to this single table. The position of
an element at [m,n] in an array of r×c elements are found in
the index-by table with the formula i := (m×(c–1))+n.
That is, in a 10×10 array, position [7,3] is at
position 66 in a single-dimensional array of
size 100. Similar calculations could be used for more than two dimensions,
but it only works when you have fixed-size dimensions. There are other
limitations best explained by Mr Feuerstein in his book.
My problem to be solved had an indeterminate number of columns (dates) and rows (data class entries per day), so this technique could not offer a direct solution. It did offer some ideas on how more complex data structures might be emulated in PL/SQL.
The Shape of the Solution
Part of the problem I faced was my knowledge of PL/SQL and its limitations; I was letting it dictate where I was willing to look for solutions. I knew that because I couldn’t do nested arrays, I didn’t consider alternatives readily. PL/SQL is a general-purpose language where one can define new data types, so it’s simply a matter of needing to adapt to the limitations. To consider how I might do this, I considered alternative options in C-like languages, knowing that I could able to adapt the solution to PL/SQL.
Figure 3 represents the data as it might be implemented in C. It’s
a single array (day_list) where each entry in that array is linked to
another array (item_list). Because it needed to be dynamically sized, I
would probably implement it as item_rec *item_list, a pointer to an item. If
I allocated memory in increments of sizeof(item_rec), then I could able to
take advantage of C pointer arithmetic and treat the pointer as if it were an
array - making it an implicitly linked list.
Most people don’t consider an array to be a linked list because it doesn’t act
like one. While most arrays or vectors are implemented as contiguous memory
blocks, this need not necessarily be the case. Any given vector class could be
implemented as a contiguous memory block or a linked list and the programmer
using that vector class should never know the difference4. The
linking relationship in an array is based on proximity, not on an explicit
link. If I modified the item_rec definition to include an explicit link to
the next item in the array, as in example 2, then the linked-list
relationship becomes explicit, allowing me to consider the implementation of
the solution from a different angle. Figure 4 shows the modified
structure graphically.
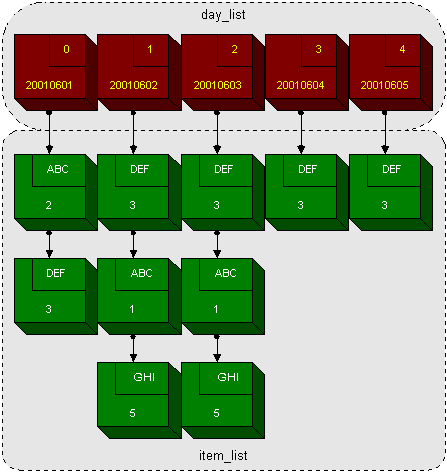
typedef struct item_rec
{
char grouping[4];
double value;
struct item_rec *next;
} item_rec;
typedef struct day_rec
{
int date; /* yyymmdd */
item_rec *item_list;
} day_rec;
day_rec *day_list;
Further analysis revealed that the solution did not need the biggest strength
of arrays: random access to the records stored in an array. I only needed to
access the records in date order and then in the order in which they appeared
in the database, so sequential access was sufficient, making it very clear
that a linked-list was most likely to lead to the “correct” implementation. It
does not, however, reach the solution, becuase PL/SQL only has automatic
memory management and references are only allowed to SQL cursor variables (in
Oracle 8i or later). Since there was no way to allocate memory
programmatically like one would with malloc or new, I needed a modified
approach for PL/SQL.
As it happens, PL/SQL had three different collection types; only one of them
was an array in the traditional sense (the varying array, VARRAY). Varying
arrays and object tables were the newest additions to the PL/SQL language and
are present to support the Oracle 8i object-relational extensions. Both data
types are very useful, but they are Oracle 8i-specific features and were not
available in Oracle 7; they also require more effort and planning to use than
normal PL/SQL index-by tables. Both varying arrays and object tables are close
in interface to arrays in other languages (the developer is responsible for
extending the array to add values to the end of the array, and the indexes are
always created in order).
The third type of collection in PL/SQL, the index-by table, was my only
option in Oracle 7. Index-by tables were sparse tables indexed by a binary
integer value—rather like a C++ std::map<int, T> or a Perl hash (using integer
keys): only one value may exist at any given index. Unlike varying arrays and
object tables, index-by tables automatically allocated the space required for
the variables in the collection, and indexes may be non-contiguous (e.g.,
1, 2, 5, 7). If the keys were created contiguously, they looked and
acted in many ways like a C array, but otherwise they allowed for smart
indexing just as a std::map<int, T> or hash allows.
To support non-contiguous indexes, PL/SQL provided alternate means for
navigating them. There were four methods associated with index-by tables:
FIRST, NEXT, PREV, and LAST. Using FIRST or LAST provided the
index of the first or last entry in the table, respectively. NEXT and PREV
were called with the index for which you wished to find the next (or previous)
index (e.g., day_list.NEXT(day_idx)). If there was nothing in the
table, FIRST and LAST would return NULL; if there was no record that
exists after (before) the requested index, NEXT (PREV) would also return
NULL. One other interesting behaviour in a non-contiguous sparse table was
that the index provided to NEXT or PREV did not need to represent a
populated index. In this way, I could have an index-by table that has values
at [5, 10, 15, 20]; NEXT(7) would return 10.
Using NEXT and PREV with an index-by table makes it appear to work much
like a doubly linked list, so if I consider the binary integer type as if it
were a pointer, I can interweave several linked lists within a single
contiguous vector.
By mapping the linked list from figure 4 to a vector structure, I
got something that looks like figure 5; example 3 shows the data
structures (in PL/SQL) to implement it. The first index-by table (day_list)
contains an index reference to the head of its item list, which is an entry in
the second index-by table (item_list). The item records have index
references to the next item in its chain, with a NULL value representing the
end of the chain for that particular entry. In this way, I’m using the
random-access nature of array indexing to my advantage while sequentially
winding my way through my linked-list imposed on top of the index-by table.
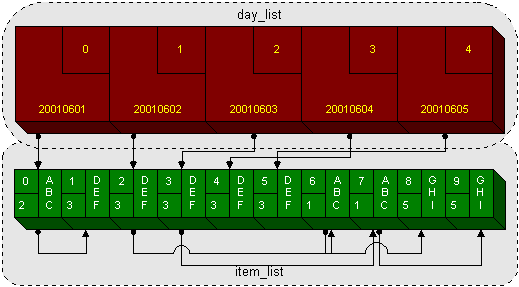
The lists in question must be treated as an inseparable pair. The “real” lists
could only be declared and allocated in one place. In Oracle 7 or Oracle 8,
that meant these needed to be declared as private package global (not
public package global, unless you wanted the users of your package
messing with these values and possibly messing up your linked list). They
could be declared these in a function and passed around as a pair to other
functions that use them, but if one parameter is IN OUT the other must be
IN OUT as well. This would not be recommended for large data sets unless you
can enforce pass-by-reference with the NOCOPY keyword.
The Solution
TYPE day_rec IS RECORD
(day_date DATE,
item_head BINARY_INTEGER);
TYPE day_tab IS TABLE OF day_rec
INDEX BY BINARY_INTEGER;
TYPE item_rec IS RECORD
(type_code VARCHAR(3),
amount NUMBER,
next_item BINARY_INTEGER,
prev_item BINARY_INTEGER);
TYPE item_tab IS TABLE OF item_rec
INDEX BY BINARY_INTEGER;
I have provided a sample implementation that reads a data value table (like table 1), parses the values according to the rules stated above (assuming a single data source) into the structures shown in example 3, and then writes the resulting data to a summary table (like table 2). In the real application for which this technique was used, the summary was kept only in memory while analysis is performed, and then only the results of the analysis were saved (in part because the summary is easily replicable). I have written the code such that a portion of the dates required can be returned in the summary table. The results are different if run for 2001–06–01—2001–06–05 and 2001–06–03—2001–06–04.
Listing 1 provides the specification for my package. I have only provided the one function as publicly visible because there is no need to expose the intimate operational details.
Listing 2 defines three different data types: data_value_tab,
which is used exclusively for the storage of the incoming data in load_data;
day_tab, which defines the daily list of values; and item_tab, which
defines the list to which the linked list will be mapped. Special attention
should be paid to how I use the index in day_tab later in the code: it
illustrates the flexibility of the sparse index-by table.
I provide a simple wrapper procedure, pl, that wraps the Oracle built-in
package DBMS_OUTPUT procedure PUT_LINE. This isn’t absolutely required,
and other debug mechanisms can be used as desired. Following pl, there are
three more private functions that are called by the implementation of
process_data: load_records, split_records, and save_records.
load_records reads the values from the DATA_VALUE table. Because I wanted
this to be able to interpret partial values, I did not immediately start
splitting the records into the data structures that I discovered solve the
overall problem.
split_records is the heart of the program. After determining the number of
data values, it gets the first and last date as Julian day values. This
conversion is significant. It gives us the number of days between the two
dates (last–first+1) and the per diem amount
(amount÷(last–first+1)). More importantly for the day_list, it
gives us a smart index for use with our index-by. The index value represents
the date on which the item_list will be used. Because we may get values out
of date order or where there might be gaps in the date order that would be
filled by division, it allows us to fill in the blanks as we need to, not as
the code forces us to.
Thus, for each date in the duration of the data value, we check to see if it’s
in the requested boundaries. If it is, then we manage our item_list. If the
date hasn’t been added yet, we know that this partial value is going to be our
first entry on the item_list and we process it as such. If we find that this
date does exist, then we need to see if this particular type_code has
already been added to the list—and if it hasn’t, we add the value to the end
of the item_list and make the required links from the previous item in the
list to the current item in the list. If the type_code already exists for
the date in question, then we simply add onto the existing record. In this
way, we obtain a structure in memory that looks substantially like figure
5 and will allow us to produce the required summary data at will,
though in a given order for the day or days in question. The key act of item
creation is item_idx := NVL(item_list.LAST, 0) + 1;.
From here, we get the last item that was created on the list (and if the list
is empty, we get a NULL value that gets transformed to 0 by NVL) and add one
to the item. In this way, we’re adding to the item vector incrementally, but
we’re maintaining the relationship in the management of the prev_item and
next_item values in the record we’re dealing with.
Finally, save_records walks through the day_list records (which need not
be contiguous, but in the sample data are contiguous) and then follows the
item_list chain for each day, saving it to the database in the DATA_OUTPUT
table. This table is the summary table that I noted would be prohibitive
space-wise, and the number of records produced suggests this very clearly: ten
output records are created in DATA_OUTPUT for four input records. This
procedure demonstrates the navigation of both non-contiguous index-by tables
and the linked list that I’ve placed on top of a contiguous index-by table.
Further Options
This technique could be made more programmatic by writing it in a package—encapsulating the functionality so that it appears to be an object—but each type of list would require its own package, because the details of the data can’t be generalized (as PL/SQL has no template support) even though the techniques used in this article are highly portable.
Lessons Learned
It’s difficult, sometimes, to think outside of the language that you’re working with. Reaching beyond the limitations of the language I was using allowed me to quickly solve the problem at hand without undertaking a change in language that would have had a prohibitive cost in time and effort. With languages like Java and C++, the option to import techniques from other languages is easier because the languages are easily extended to handle new data structures with user-defined data types, but as long as a language supports a minimum set of features (user-definable types and arrays that can be composed of user-definable types), this particular implementation could be carried to any programming language at all.
One of the reasons I try to stay aware of the capabilities of and practice with multiple programming languages is so that I have a variety of ways of looking at a problem. Because of this tendency early in my career, I was able to identify the way that I might solve this problem with the limited time available for the project. I intend to use this experience to remind me of the necessity of constantly looking elsewhere for the ideas to solve the problems at hand—and creatively applying the ideas that I find with the capabilities of the language of the problem at hand.
Source Listings
All of the source code presented here is copyright © 2002–2014 Austin Ziegler and is available under the MIT licence.
-- data_split_pkg.sql
CREATE OR REPLACE PACKAGE data_split AS
info_data_split_pkg CONSTANT VARCHAR2(120) := 'Version 1.0';
PROCEDURE process_data
(start_date IN DATE DEFAULT SYSDATE,
end_date IN DATE DEFAULT SYSDATE,
debug IN BOOLEAN DEFAULT FALSE);
END data_split;
-- data_split_pkg_body.sql
CREATE OR REPLACE PACKAGE BODY data_split AS
info_data_split_body CONSTANT VARCHAR2(120) := 'Version 1.0';
TYPE data_value_tab IS TABLE OF data_values%ROWTYPE
INDEX BY BINARY_INTEGER;
TYPE day_rec IS RECORD
(day_date DATE,
item_head BINARY_INTEGER);
TYPE day_tab IS TABLE OF day_rec
INDEX BY BINARY_INTEGER;
TYPE item_rec IS RECORD
(type_code VARCHAR(3),
amount NUMBER,
next_item BINARY_INTEGER,
prev_item BINARY_INTEGER);
TYPE item_tab IS TABLE OF item_rec
INDEX BY BINARY_INTEGER;
debug_on BOOLEAN := FALSE;
PROCEDURE pl(lo IN VARCHAR) IS
BEGIN
IF (debug_on) THEN
DBMS_OUTPUT.PUT_LINE(lo);
END IF;
END pl;
-- This loads the records that started, ended, were contained in,
-- or contained the specified start and end date. Split records
-- will pull only the pieces we need.
PROCEDURE load_records
(date_start IN DATE,
date_end IN DATE,
value_list IN OUT data_value_tab) IS
CURSOR get_values_cur
(start_date_in DATE,
end_date_in DATE) IS
SELECT dv.type_code, TRUNC(dv.start_date) start_date,
TRUNC(dv.end_date) end_date, dv.amount
FROM data_values dv
WHERE TRUNC(dv.start_date)
BETWEEN start_date_in AND end_date_in
OR start_date_in
BETWEEN TRUNC(dv.start_date) AND (dv.end_date)
OR TRUNC(dv.end_date)
BETWEEN start_date_in AND end_date_in
OR end_date_in
BETWEEN TRUNC(dv.start_date) AND TRUNC(dv.end_date);
value_idx BINARY_INTEGER := 0;
BEGIN
-- Initialise the value list.
value_list.DELETE;
FOR gvlc IN get_values_cur(date_start, date_end)
LOOP
value_idx := value_idx + 1;
value_list(value_idx) := gvlc;
pl('# : ' || value_idx);
pl('type_code : ' || gvlc.type_code);
pl('dates : ' || gvlc.start_date ||
' - ' || gvlc.end_date);
pl('amount : ' || gvlc.amount);
END LOOP;
END load_records;
PROCEDURE split_records
(start_date IN DATE,
end_date IN DATE,
value_list IN data_value_tab,
day_list IN OUT day_tab,
item_list IN OUT item_tab) IS
value_idx BINARY_INTEGER;
item_idx BINARY_INTEGER := 0;
prev_idx BINARY_INTEGER;
link_idx BINARY_INTEGER;
rec_days PLS_INTEGER;
rec_days_amt NUMBER;
first_jul_day BINARY_INTEGER;
last_jul_day BINARY_INTEGER;
test_date DATE;
BEGIN
-- Initialise values
day_list.DELETE;
item_list.DELETE;
pl('# of values: ' || value_list.COUNT);
value_idx := value_list.FIRST;
WHILE (value_idx IS NOT NULL)
LOOP
pl('Processing Value Record: ' || value_idx);
-- Get the first day and last day in Julian terms.
first_jul_day := TO_NUMBER(
TO_CHAR(value_list(value_idx).start_date, 'J')
);
last_jul_day := TO_NUMBER(
TO_CHAR(value_list(value_idx).end_date, 'J')
);
-- Figure out the amount per day.
rec_days_amt := value_list(value_idx).amount /
(last_jul_day - first_jul_day + 1);
pl('Value Record ' || value_list(value_idx).type_code ||
' [' || first_jul_day || ' - ' || last_jul_day ||
': ' || rec_days_amt || ' per day]');
FOR jul_idx IN first_jul_day .. last_jul_day
LOOP
pl('Julian: ' || jul_idx);
test_date := TO_DATE(TO_CHAR(jul_idx), 'J');
-- Make sure that we're within the boundaries.
IF ( (test_date >= start_date)
AND (test_date <= end_date)) THEN
pl('In Date Boundaries');
-- If we are, start applying the amount per day.
IF (day_list.EXISTS(jul_idx)) THEN
-- We've found a list already extant at the
-- current date. Reuse it.
pl('Day exists.');
item_idx := day_list(jul_idx).item_head;
prev_idx := NULL;
link_idx := NULL;
-- Look for our type_code.
WHILE (item_idx IS NOT NULL)
LOOP
IF (item_list(item_idx).type_code =
value_list(value_idx).type_code) THEN
-- Found a matching record.
link_idx := item_idx;
item_idx := NULL;
pl('Matching record found at ' || item_idx);
ELSE
prev_idx := item_idx;
item_idx := item_list(prev_idx).next_item;
END IF;
END LOOP;
-- No such type_code, add a new record.
IF (link_idx IS NULL) THEN
item_idx := NVL(item_list. LAST, 0) + 1;
item_list(item_idx).type_code :=
value_list(value_idx).type_code;
item_list(item_idx).amount := rec_days_amt;
item_list(item_idx).prev_item := prev_idx;
item_list(item_idx).next_item := NULL;
item_list(prev_idx).next_item := item_idx;
pl('New record added.');
ELSE -- We have a match: increase by the daily amount.
item_list(link_idx).amount :=
item_list(link_idx).amount + rec_days_amt;
pl('Existing record increased.');
END IF;
ELSE -- No charges yet at this date.
item_idx := NVL(item_list. LAST, 0) + 1;
day_list(jul_idx).day_date := test_date;
day_list(jul_idx).item_head := item_idx;
item_list(item_idx).type_code :=
value_list(value_idx).type_code;
item_list(item_idx).amount := rec_days_amt;
item_list(item_idx).prev_item := NULL;
item_list(item_idx).next_item := NULL;
pl('New date and record added.');
END IF;
END IF;
END LOOP;
value_idx := value_list.NEXT(value_idx);
END LOOP;
pl('# of days : ' || day_list.COUNT);
pl('# of items: ' || item_list.COUNT);
END split_records;
PROCEDURE save_records
(day_list IN day_tab,
item_list IN item_tab) IS
day_idx BINARY_INTEGER;
item_idx BINARY_INTEGER;
BEGIN
pl('# of days : ' || day_list.COUNT);
pl('# of items: ' || item_list.COUNT);
day_idx := day_list.FIRST;
WHILE (day_idx IS NOT NULL)
LOOP
pl('Processing day [' || day_idx || ', ' ||
TO_CHAR(TO_DATE(day_idx, 'J'), 'YYYY-MM-DD') ||
'].');
item_idx := day_list(day_idx).item_head;
WHILE (item_idx IS NOT NULL)
LOOP
pl('Item [' || item_idx || ']: [' ||
item_list(item_idx).type_code || ': ' ||
item_list(item_idx).amount || ']');
INSERT
INTO data_output(data_date, type_code, amount)
VALUES (day_list(day_idx).day_date,
item_list(item_idx).type_code,
item_list(item_idx).amount);
item_idx := item_list(item_idx).next_item;
END LOOP;
day_idx := day_list.NEXT(day_idx);
END LOOP;
END save_records;
PROCEDURE process_data
(start_date IN DATE DEFAULT SYSDATE,
end_date IN DATE DEFAULT SYSDATE,
debug IN BOOLEAN DEFAULT FALSE) IS
v_list data_value_tab;
d_list day_tab;
i_list item_tab;
BEGIN
debug_on := debug;
pl('Start : ' || start_date);
pl('Stop : ' || end_date);
load_records(start_date, end_date, v_list);
split_records(start_date, end_date, v_list, d_list, i_list);
save_records(d_list, i_list);
END process_data;
END data_split;
-- (data_split_tables.sql)
CREATE TABLE data_values
(type_code CHAR(3)
CONSTRAINT nn_data_values_tc NOT NULL,
start_date DATE DEFAULT SYSDATE
CONSTRAINT nn_data_values_sd NOT NULL,
end_date DATE DEFAULT SYSDATE
CONSTRAINT nn_data_values_ed NOT NULL,
amount NUMBER DEFAULT 0
CONSTRAINT nn_data_values_am NOT NULL,
PRIMARY KEY pk_data_values (type_code, start_date, end_date));
CREATE TABLE data_output
(data_date DATE DEFAULT SYSDATE
CONSTRAINT nn_data_output_dd NOT NULL,
type_code CHAR(3)
CONSTRAINT nn_data_output_do NOT NULL,
amount NUMBER DEFAULT 0
CONSTRAINT nn_data_output_am NOT NULL,
PRIMARY KEY pk_data_output (data_date, type_code));
ALTER SESSION SET NLS_DATE_FORMAT = 'yyyymmdd';
INSERT
INTO data_values(type_code, start_date, end_date, amount)
VALUES ('ABC', '20010601', '20010601', 1);
INSERT
INTO data_values(type_code, start_date, end_date, amount)
VALUES ('DEF', '20010601', '20010605', 15);
INSERT
INTO data_values(type_code, start_date, end_date, amount)
VALUES ('ABC', '20010601', '20010603', 3);
INSERT
INTO data_values(type_code, start_date, end_date, amount)
VALUES ('GHI', '20010602', '20010603', 10);
COMMIT;
-- test_data_split.sql
BEGIN
DELETE
FROM data_output;
data_split.process_data(TO_DATE('20010601', 'yyyymmdd'),
TO_DATE('20010605', 'yyyymmdd'), TRUE);
data_split.process_data(TO_DATE('20010601', 'yyyymmdd'),
TO_DATE('20010603', 'yyyymmdd'));
COMMIT;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('CODE: ' || SQLCODE);
DBMS_OUTPUT.PUT_LINE('MSG : ' || SQLERRM);
END;
SELECT *
FROM data_output
ORDER BY type_code;
- This was done in a later project that took roughly twice as long as this project did. ↩
- It is entirely possible that Oracle PL/SQL has been modified to remove this limitation. The technique presented here is still useful. ↩
- When I wrote this code, Oracle PL/SQL Programming was in its second edition, published in 1998. As of 2014 the most recent version is the sixth edition. ↩
- For many years, Apple did this with class clusters like
NSArrayorNSDictionary. The internal implementation might change based on the amount of data stored in the array or dictionary object. ↩
- 2014-09-25: Book references have been updated to current releases and a general editing cleanup was performed. Amazon affiliate links have been added.[ back ]